Life as a Condition of Cosmology
Trigger Warnings: Bayesian Probability and the Anthropic Principle!
Once upon a time I was involved in setting up a cosmology conference in Valencia (Spain). The principal advantage of being among the organizers of such a meeting is that you get to invite yourself to give a talk and to choose the topic. On this particular occasion, I deliberately abused my privilege and put myself on the programme to talk about the “Anthropic Principle”. I doubt if there is any subject more likely to polarize a scientific audience than this. About half the participants present in the meeting stayed for my talk. The other half ran screaming from the room. Hence the trigger warnings on this post. Anyway, I noticed a tweet this morning from Jon Butterworth advertising a new blog post of his on the very same subject so I thought I’d while away a rainy November afternoon with a contribution of my own.
In case you weren’t already aware, the Anthropic Principle is the name given to a class of ideas arising from the suggestion that there is some connection between the material properties of the Universe as a whole and the presence of human life within it. The name was coined by Brandon Carter in 1974 as a corrective to the “Copernican Principle” that man does not occupy a special place in the Universe. A naïve application of this latter principle to cosmology might lead us to think that we could have evolved in any of the myriad possible Universes described by the system of Friedmann equations. The Anthropic Principle denies this, because life could not have evolved in all possible versions of the Big Bang model. There are however many different versions of this basic idea that have different logical structures and indeed different degrees of credibility. It is not really surprising to me that there is such a controversy about this particular issue, given that so few physicists and astronomers take time to study the logical structure of the subject, and this is the only way to assess the meaning and explanatory value of propositions like the Anthropic Principle. My former PhD supervisor, John Barrow (who is quoted in John Butterworth’s post) wrote the definite text on this topic together with Frank Tipler to which I refer you for more background. What I want to do here is to unpick this idea from a very specific perspective and show how it can be understood quite straightfowardly in terms of Bayesian reasoning. I’ll begin by outlining this form of inferential logic.
I’ll start with Bayes’ theorem which for three logical propositions (such as statements about the values of parameters in theory) A, B and C can be written in the form

where

This is (or should be!) uncontroversial as it is simply a result of the sum and product rules for combining probabilities. Notice, however, that I’ve not restricted it to two propositions A and B as is often done, but carried throughout an extra one (C). This is to emphasize the fact that, to a Bayesian, all probabilities are conditional on something; usually, in the context of data analysis this is a background theory that furnishes the framework within which measurements are interpreted. If you say this makes everything model-dependent, then I’d agree. But every interpretation of data in terms of parameters of a model is dependent on the model. It has to be. If you think it can be otherwise then I think you’re misguided.
In the equation, P(B|C) is the probability of B being true, given that C is true . The information C need not be definitely known, but perhaps assumed for the sake of argument. The left-hand side of Bayes’ theorem denotes the probability of B given both A and C, and so on. The presence of C has not changed anything, but is just there as a reminder that it all depends on what is being assumed in the background. The equation states a theorem that can be proved to be mathematically correct so it is – or should be – uncontroversial.
To a Bayesian, the entities A, B and C are logical propositions which can only be either true or false. The entities themselves are not blurred out, but we may have insufficient information to decide which of the two possibilities is correct. In this interpretation, P(A|C) represents the degree of belief that it is consistent to hold in the truth of A given the information C. Probability is therefore a generalization of the “normal” deductive logic expressed by Boolean algebra: the value “0” is associated with a proposition which is false and “1” denotes one that is true. Probability theory extends this logic to the intermediate case where there is insufficient information to be certain about the status of the proposition.
A common objection to Bayesian probability is that it is somehow arbitrary or ill-defined. “Subjective” is the word that is often bandied about. This is only fair to the extent that different individuals may have access to different information and therefore assign different probabilities. Given different information C and C′ the probabilities P(A|C) and P(A|C′) will be different. On the other hand, the same precise rules for assigning and manipulating probabilities apply as before. Identical results should therefore be obtained whether these are applied by any person, or even a robot, so that part isn’t subjective at all.
In fact I’d go further. I think one of the great strengths of the Bayesian interpretation is precisely that it does depend on what information is assumed. This means that such information has to be stated explicitly. The essential assumptions behind a result can be – and, regrettably, often are – hidden in frequentist analyses. Being a Bayesian forces you to put all your cards on the table.
To a Bayesian, probabilities are always conditional on other assumed truths. There is no such thing as an absolute probability, hence my alteration of the form of Bayes’s theorem to represent this. A probability such as P(A) has no meaning to a Bayesian: there is always conditioning information. For example, if I blithely assign a probability of 1/6 to each face of a dice, that assignment is actually conditional on me having no information to discriminate between the appearance of the faces, and no knowledge of the rolling trajectory that would allow me to make a prediction of its eventual resting position.
In tbe Bayesian framework, probability theory becomes not a branch of experimental science but a branch of logic. Like any branch of mathematics it cannot be tested by experiment but only by the requirement that it be internally self-consistent. This brings me to what I think is one of the most important results of twentieth century mathematics, but which is unfortunately almost unknown in the scientific community. In 1946, Richard Cox derived the unique generalization of Boolean algebra under the assumption that such a logic must involve associated a single number with any logical proposition. The result he got is beautiful and anyone with any interest in science should make a point of reading his elegant argument. It turns out that the only way to construct a consistent logic of uncertainty incorporating this principle is by using the standard laws of probability. There is no other way to reason consistently in the face of uncertainty than probability theory. Accordingly, probability theory always applies when there is insufficient knowledge for deductive certainty. Probability is inductive logic.
This is not just a nice mathematical property. This kind of probability lies at the foundations of a consistent methodological framework that not only encapsulates many common-sense notions about how science works, but also puts at least some aspects of scientific reasoning on a rigorous quantitative footing. This is an important weapon that should be used more often in the battle against the creeping irrationalism one finds in society at large.
To see how the Bayesian approach provides a methodology for science, let us consider a simple example. Suppose we have a hypothesis H (some theoretical idea that we think might explain some experiment or observation). We also have access to some data D, and we also adopt some prior information I (which might be the results of other experiments and observations, or other working assumptions). What we want to know is how strongly the data D supports the hypothesis H given my background assumptions I. To keep it easy, we assume that the choice is between whether H is true or H is false. In the latter case, “not-H” or H′ (for short) is true. If our experiment is at all useful we can construct P(D|HI), the probability that the experiment would produce the data set D if both our hypothesis and the conditional information are true.
The probability P(D|HI) is called the likelihood; to construct it we need to have some knowledge of the statistical errors produced by our measurement. Using Bayes’ theorem we can “invert” this likelihood to give P(H|DI), the probability that our hypothesis is true given the data and our assumptions. The result looks just like we had in the first two equations:
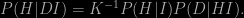
Now we can expand the “normalising constant” K because we know that either H or H′ must be true. Thus
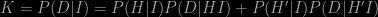
The P(H|DI) on the left-hand side of the first expression is called the posterior probability; the right-hand side involves P(H|I), which is called the prior probability and the likelihood P(D|HI). The principal controversy surrounding Bayesian inductive reasoning involves the prior and how to define it, which is something I’ll comment on in a future post.
The Bayesian recipe for testing a hypothesis assigns a large posterior probability to a hypothesis for which the product of the prior probability and the likelihood is large. It can be generalized to the case where we want to pick the best of a set of competing hypothesis, say H1 …. Hn. Note that this need not be the set of all possible hypotheses, just those that we have thought about. We can only choose from what is available. The hypothesis may be relatively simple, such as that some particular parameter takes the value x, or they may be composite involving many parameters and/or assumptions. For instance, the Big Bang model of our universe is a very complicated hypothesis, or in fact a combination of hypotheses joined together, involving at least a dozen parameters which can’t be predicted a priori but which have to be estimated from observations.
The required result for multiple hypotheses is pretty straightforward: the sum of the two alternatives involved in K above simply becomes a sum over all possible hypotheses, so that

and

If the hypothesis concerns the value of a parameter – in cosmology this might be, e.g., the mean density of the Universe expressed by the density parameter Ω0 – then the allowed space of possibilities is continuous. The sum in the denominator should then be replaced by an integral, but conceptually nothing changes. Our “best” hypothesis is the one that has the greatest posterior probability.
From a frequentist stance the procedure is often instead to just maximize the likelihood. According to this approach the best theory is the one that makes the data most probable. This can be the same as the most probable theory, but only if the prior probability is constant, but the probability of a model given the data is generally not the same as the probability of the data given the model. I’m amazed how many practising scientists make this error on a regular basis.
The following figure might serve to illustrate the difference between the frequentist and Bayesian approaches. In the former case, everything is done in “data space” using likelihoods, and in the other we work throughout with probabilities of hypotheses, i.e. we think in hypothesis space. I find it interesting to note that most theorists that I know who work in cosmology are Bayesians and most observers are frequentists!

As I mentioned above, it is the presence of the prior probability in the general formula that is the most controversial aspect of the Bayesian approach. The attitude of frequentists is often that this prior information is completely arbitrary or at least “model-dependent”. Being empirically-minded people, by and large, they prefer to think that measurements can be made and interpreted without reference to theory at all.
Assuming we can assign the prior probabilities in an appropriate way what emerges from the Bayesian framework is a consistent methodology for scientific progress. The scheme starts with the hardest part – theory creation. This requires human intervention, since we have no automatic procedure for dreaming up hypothesis from thin air. Once we have a set of hypotheses, we need data against which theories can be compared using their relative probabilities. The experimental testing of a theory can happen in many stages: the posterior probability obtained after one experiment can be fed in, as prior, into the next. The order of experiments does not matter. This all happens in an endless loop, as models are tested and refined by confrontation with experimental discoveries, and are forced to compete with new theoretical ideas. Often one particular theory emerges as most probable for a while, such as in particle physics where a “standard model” has been in existence for many years. But this does not make it absolutely right; it is just the best bet amongst the alternatives. Likewise, the Big Bang model does not represent the absolute truth, but is just the best available model in the face of the manifold relevant observations we now have concerning the Universe’s origin and evolution. The crucial point about this methodology is that it is inherently inductive: all the reasoning is carried out in “hypothesis space” rather than “observation space”. The primary form of logic involved is not deduction but induction. Science is all about inverse reasoning.
Now, back to the anthropic principle. The point is that we can observe that life exists in our Universe and this observation must be incorporated as conditioning information whenever we try to make inferences about cosmological models if we are to reason consistently. In other words, the existence of life is a datum that must be incorporated in the conditioning information I mentioned above.
Suppose we have a model of the Universe M that contains various parameters which can be fixed by some form of observation. Let U be the proposition that these parameters take specific values U1, U2, and so on. Anthropic arguments revolve around the existence of life, so let L be the proposition that intelligent life evolves in the Universe. Note that the word “anthropic” implies specifically human life, but many versions of the argument do not necessarily accommodate anything more complicated than a virus.
Using Bayes’ theorem we can write
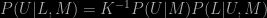
The dependence of the posterior probability P(U|L,M) on the likelihood P(L|U,M) demonstrates that the values of U for which P(L|U,M) is larger correspond to larger values of P(U|L,M); K is just a normalizing constant for the purpose of this argument. Since life is observed in our Universe the model-parameters which make life more probable must be preferred to those that make it less so. To go any further we need to say something about the likelihood and the prior. Here the complexity and scope of the model makes it virtually impossible to apply in detail the symmetry principles usually exploited to define priors for physical models. On the other hand, it seems reasonable to assume that the prior is broad rather than sharply peaked; if our prior knowledge of which universes are possible were so definite then we wouldn’t really be interested in knowing what observations could tell us. If now the likelihood is sharply peaked in U then this will be projected directly into the posterior distribution.
We have to assign the likelihood using our knowledge of how galaxies, stars and planets form, how planets are distributed in orbits around stars, what conditions are needed for life to evolve, and so on. There are certainly many gaps in this knowledge. Nevertheless if any one of the steps in this chain of knowledge requires very finely-tuned parameter choices then we can marginalize over the remaining steps and still end up with a sharp peak in the remaining likelihood and so also in the posterior probability. For example, there are plausible reasons for thinking that intelligent life has to be carbon-based, and therefore evolve on a planet. It is reasonable to infer, therefore, that P(U|L,M) should prefer some values of U. This means that there is a correlation between the propositions U and L in the sense that knowledge of one should, through Bayesian reasoning, enable us to make inferences about the other.
It is very difficult to make this kind of argument rigorously quantitative, but I can illustrate how the argument works with a simplified example. Let us suppose that the relevant parameters contained in the set U include such quantities as Newton’s gravitational constant G, the charge on the electron e, and the mass of the proton m. These are usually termed fundamental constants. The argument above indicates that there might be a connection between the existence of life and the value that these constants jointly take. Moreover, there is no reason why this kind of argument should not be used to find the values of fundamental constants in advance of their measurement. The ordering of experiment and theory is merely an historical accident; the process is cyclical. An illustration of this type of logic is furnished by the case of a plant whose seeds germinate only after prolonged rain. A newly-germinated (and intelligent) specimen could either observe dampness in the soil directly, or infer it using its own knowledge coupled with the observation of its own germination. This type, used properly, can be predictive and explanatory.
This argument is just one example of a number of its type, and it has clear (but limited) explanatory power. Indeed it represents a fruitful application of Bayesian reasoning. The question is how surprised we should be that the constants of nature are observed to have their particular values? That clearly requires a probability based answer. The smaller the probability of a specific joint set of values (given our prior knowledge) then the more surprised we should be to find them. But this surprise should be bounded in some way: the values have to lie somewhere in the space of possibilities. Our argument has not explained why life exists or even why the parameters take their values but it has elucidated the connection between two propositions. In doing so it has reduced the number of unexplained phenomena from two to one. But it still takes our existence as a starting point rather than trying to explain it from first principles.
Arguments of this type have been called Weak Anthropic Principle by Brandon Carter and I do not believe there is any reason for them to be at all controversial. They are simply Bayesian arguments that treat the existence of life as an observation about the Universe that is treated in Bayes’ theorem in the same way as all other relevant data and whatever other conditioning information we have. If more scientists knew about the inductive nature of their subject, then this type of logic would not have acquired the suspicious status that it currently has.
Follow @telescoper
November 7, 2015 at 9:57 pm
Nice post. A note – I don’t think that Cox’s theorem uncontroversially singles out the uniqueness of probability theory. I don’t have the refs on hand but, for example, my understanding is that fuzzy logic and other systems satisfy the key axioms and stronger assumptions (priors?!) are required to obtain uniqueness of probability theory.
November 7, 2015 at 10:22 pm
What Cox showed is that if you associate a number with the strength with which the assumed truth of one binary proposition implies the truth of another, based on the known relations between their referents, then this “strength of implication” satisfies two mathematical rules, which just happen to be the sum and product rules of probability theory. On these grounds and on the grounds that strength of implication is what you actually want whenever you meet a problem that involves uncertainty, I am happy to identify probability as strength of implication. But if frequentists or philosophers or anybody else objects then there is no need to argue – just say “OK, strength of implication is what I want, here is how to calculate it, I’ll go solve the problem while you are playing around with words.”
There are one or two minor unobjectionable extra axioms that Cox needs, but only philosophical pedants make anything of them.
November 7, 2015 at 10:48 pm
I’m not a frequentist, bayesian or philosopher. Maybe an occasional pedant. Just thought it was interesting.
I’m OK with underdetermination, and certainly don’t think it should stop people from solving problems by making stronger assumptions 🙂
November 8, 2015 at 12:12 am
I don’t know if Sean is familiar with the argument that Michael Ikeda and I made in the late 1990s, which states a similar point of view to what Sean writes here, in particular the necessity to condition on your own existence as background information when making inferences about cosmological physical constants:
http://bayesrules.net/anthropic.html
This was reprinted in Martin & Monnier, “The Improbability of God” (Prometheus 2006)
November 8, 2015 at 5:02 am
I had thought that this was by Sean Carroll, but it’s by someone else, and I can’t figure out who it is because the name isn’t obviously available (or I can’t find it) on the blog. It was pointed to by another blog by Sean Carroll, which is why I made that mistake!
Anyway, I would be interested in learning what the author knows of the article that Michael and I posted!
November 8, 2015 at 5:09 am
Sorry, I’ve now locate the link to Peter Coles.
So I’d be interested to learn what Peter knows of our earlier work.
November 8, 2015 at 9:23 am
Peter and I wrote a paper on the anthropic principle, using Bates to distinguish the sense from the nonsense, in the 1990s.
November 8, 2015 at 9:23 am
Oops, that’s Bayes.
November 8, 2015 at 1:35 pm
Anton, I’d be interested in reading your paper with Peter if it’s available. Do you have a link, or could you send me a copy (bill (AT) bayesrules.net)?
November 8, 2015 at 3:34 pm
The reference is A.J.M. Garrett and P. Coles, Comments on Astrophysics 17 23-47 (1993).
I’m afraid it’s not available online – not even through ADS (although I will maybe try to fix that). I also lost the original latex file. But I do have a hard copy of the published article which I can get scanned.
November 8, 2015 at 4:06 pm
I’ll look for it the next time I’m at the University. Meantime, thanks for the reference, Peter!
November 8, 2015 at 4:15 pm
Peter, I checked the University of Vermont library and they don’t appear to have that volume. The University of Texas does, but I’m 2000 miles away so it’s not very convenient 😦
So if you could scan that article (at your convenience) and email the scan to me, I’d be very grateful. My email is above.
Thanks, Bill
November 8, 2015 at 1:20 pm
A necessity indeed. Luke Barnes attempted to evade it in his critique of your argument here.
November 8, 2015 at 1:32 pm
Yes, Luke & I had a back-and-forth on this in email, he obviously doesn’t get it.
November 8, 2015 at 9:44 pm
bayesrules,
Would you be OK with me publishing our short email exchange on my blog (Letters to Nature)? Then people can decide for themselves whether I don’t get it. You made similar comments about my post over at Sean Carroll’s blog. I can send the blog post to you first before I post it, for your approval.
November 9, 2015 at 7:07 pm
Available quantitative data on the preponderance of life seems ignored in the analysis cited.
Based on percentages of mass, volume, or pretty much any metric one might use, “life more complex than a virus” occupies approximately 0% of the known universe, which seems to undermine any fine tuning claim to “friendliness”.
If designed, our reality seems oriented to a VERY anti-social universe, apparently geared to being about as hostile to life as we know it as one might imagine.
I get the feeling this astonishing oversight is to support a/some god-concept(s). Am I missing something?
November 9, 2015 at 7:11 pm
Small changes in fundamental properties of the Universe, such as the fine structure constant, would make life totally impossible. The Universe is constructed in such a way as to make life at least possible.
November 9, 2015 at 7:24 pm
Is this not a natural side-effect of defining the scope of any measured outcome so narrowly as to be statistically zero relative to the total sample size?
If there is an example where this is not the case, I’d like to know what it was…
In other words, taking any 1 in more-than-a-gazillion event, (like any of the conflicting definitions of life in the paper), and pointing out that the slightest change in the conditions that gave rise to it would make the event impossible seems to miss an important point about clear reasoning and lottery fallacies, doesn’t it?
November 9, 2015 at 7:35 pm
The need to take this selection effect into account is precisely the point of my piece.
November 9, 2015 at 9:18 pm
I didn’t recall seeing the lottery fallacy mentioned anywhere. Nope…
One normally expects some reference to the precise point of a piece in the conclusion, but after a couple of readings, I’m unable to infer anything like that. Can you point me to somewhere this point is summarized, clearly stated, or easily inferred?
November 9, 2015 at 9:19 pm
I didn’t say I mentioned the lottery fallacy.
November 9, 2015 at 9:34 pm
It’s true you did not use those words – however, when I mentioned advocacy of the anthropic principles to be side-effects of the lottery fallacy (“defining the scope of any measured outcome so narrowly as to be statistically zero relative to the total sample size”), you responded by referring to “this selection effect”.
I took that to refer to what I’d just mentioned.
If you meant to refer to a different selection effect than the one I was asking about, OK….Then what did you mean?
November 9, 2015 at 9:42 pm
I meant the selection effect that the entire post is about.
November 9, 2015 at 9:49 pm
Oh, I get it….didn’t catch the context.
I’m going to join you with a nice Chilean Carmenere from up north (from Patagonia, anyway).
Cheers! 🙂
November 8, 2015 at 5:03 am
I have to wonder if anyone else is concerned about the amount of ceteris paribus and begging the question components in framing this reasoning?
It seems plausible to consider these arguments if “complexity”, “intelligence”, etc., were defined with some reasonable precision, why the virus is a reasonably valid limiting case, and so on.
November 8, 2015 at 5:11 am
(Also posted on facebook.) You say: “Now, back to the anthropic principle. The point is that we can observe that life exists in our Universe and this observation must be incorporated as conditioning information whenever we try to make inferences about cosmological models if we are to reason consistently.” Why is this the point? We can observe so much more than that life exists. We can observe the values of G and c and e and hbar. We can observe the distribution of galaxies, and of the wealth of nations. *Life*, it seems to me, is nothing special. The theories we prefer have to account for everything we observe.
This obsession about “life” is relevant (perhaps) to something different: whether, in a multiverse theory, *our* universe is somehow typical. I don’t pretend to know whether this is something we should worry about, or even a sensible question. But it is quite removed from the straight-forward Bayesian reasoning you describe.
November 8, 2015 at 9:11 am
My article (linked near the top) is actually from Feb last year, re-shared because meeting John Barrow again last week reminded me of it. But glad it led to this – good article.
So, from the existence of your article Peter, one could induce something about the seating plan at the IoP awards ceremony.
November 8, 2015 at 4:41 pm
Did they put all the cranks together?
😉
November 9, 2015 at 9:35 am
Many make a hypothesis for reason. Art of rhetoric could be used.
As always the set of presumtions building and represent the limit of understanding.
November 9, 2015 at 10:13 am
By nature a population itself is not limited in understanding each other.
November 9, 2015 at 10:53 am
Yes. Peter and I used Bayes as the razor to separate out the good stuff from the bad.
November 9, 2015 at 11:00 am
There’s quite a lot of stuff in the Barrow & Tipler book about overtly teleological versions of the anthropic principle, which quite distinct from the sensible versions.
November 10, 2015 at 1:29 am
Hi again, Phillip Helbig. For my reply to Prof. Lawrence M. Krauss’s review which you cite (viz., Lawrence Krauss, “More dangerous than nonsense”, New Scientist, Vol. 194, No. 2603 [May 12, 2007], p. 53) of Prof. Frank J. Tipler’s book The Physics of Christianity (New York: Doubleday, 2007), see pp. 27-28 of my following article, which also details Tipler’s Omega Point cosmology and the Feynman-DeWitt-Weinberg quantum gravity/Standard Model Theory of Everything (TOE):
* James Redford, “The Physics of God and the Quantum Gravity Theory of Everything”, Social Science Research Network (SSRN), Sept. 10, 2012 (orig. pub. Dec. 19, 2011), 186 pp., doi:10.2139/ssrn.1974708, https://archive.org/download/ThePhysicsOfGodAndTheQuantumGravityTheoryOfEverything/Redford-Physics-of-God.pdf .
For my commentary on Profs. Tipler and Krauss’s June 3, 2007 debate at the California Institute of Technology, see my below article:
* James Redford, “Video of Profs. Frank Tipler and Lawrence Krauss’s Debate at Caltech: Can Physics Prove God and Christianity?”, alt.sci.astro, Message-ID: jghev8tcbv02b6vn3uiq8jmelp7jijluqk[at sign]4ax[period]com , July 30, 2013, https://groups.google.com/forum/#!topic/alt.sci.astro/KQWt4KcpMVo .
Helbig, you state that “Sometime after publication of this book [The Anthropic Cosmological Principle], Tipler went off the deep end and hasn’t yet resurfaced.” Prof. Tipler has been doing exceedingly good work indeed since the publication of that book in 1986, e.g., his Omega Point cosmology has been published and extensively peer-reviewed in leading physics journals. Some of his work is covered in my two foregoing articles, but see also Tipler’s following paper demonstrating the existence of the multiverse of the Many-Worlds Interpretation:
* Frank J. Tipler, “Quantum nonlocality does not exist”, Proceedings of the National Academy of Sciences of the United States of America (PNAS), Vol. 111, No. 31 (Aug. 5, 2014), pp. 11281-11286, doi:10.1073/pnas.1324238111.
November 10, 2015 at 9:32 am
I’ve not read Tipler’s “Physics of Christianity” book but at some time in some library I took the trouble to read in his own words (not in his book with Barrow) his writing about the Omega Point. Let me declare my interest: as well as being a research physicist on the border between physics and probability theory I am an evangelical Christian. I believe that the Bible and the laws of physics are in perfect accord, with the exception of miracles; with those you have to choose, and when I converted from atheism 25 years ago my choice changed. Today I take the view that God put in place the laws of physics (hence their beauty) and God is therefore able and has the right to break them if he wishes – which he sometimes does to make a point to human beings. I say that not to provoke discussion but as background to what I say next.
The starting point for Tipler’s Omega Point ideas was, obviously, the work of Teilhard de Chardin in the 1950s. My objection to Tipler’s development, however, is that it is silent on the whole point of the New Testament, namely man’s inability to live well (history is a tale of war after war and today we have WMDs…), and how God offers us help. Neither does Tipler’s work, to my knowledge, single out any one religion – a fact that will irritate followers of every religion!
November 10, 2015 at 4:10 pm
Tipler claims that quantum nonlocality is a consequence of the classical-observer/quantum-system artificial dichotomy. He also claims that the problem is resolved upon adopting the many-worlds interpretation of quantum mechanics.
This is wrong. First, nonlocality is inferred by comparing the observations made in certain experiments against a locality criterion. The observations violate the locality criterion. Ergo, nonlocality. That the statistics of the observations are correctly predicted by quantum mechanics is irrelevant. Equally irrelevant to the conclusion is the fact that the necessary experimental set-up was inspired by John Bell’s deep familiarity with quantum theory.
Second, the many-worlds interpretation of quantum mechanics is just that – an interpretation. No testable predictions differ. Locality is testable, however. So, even if many-worlds is a good way of thinking about quantum theory, it can’t help. On top of which it is a lousy way of thinking about quantum mechanics. For, a measurement involves an interaction between the measuring apparatus and the system; consequently, the apparatus and system could be considered quantum-mechanically as a joint system. There would be splitting into many worlds if you treat the system as quantum and treat the apparatus as classical, but no splitting if you treat them jointly as quantum. Physicists are free to analyse the situation in these differing ways, but they would then disagree about whether splitting has taken place. That’s inconsistent, and therefore unacceptable even in a gedanken-experiment.
Here is Tipler on part of his theology:
http://129.81.170.14/~tipler/summary.html
He doesn’t know enough about Hebrew verbs. He translates God’s words EHYEH ASHER EHYEH (in Exodus 3:14) as “I shall be what I shall be.” He places great stress on the fact it is a future tense. But many Bible translations render it as “I am what/who I am.” In fact they are both right, and both inadequate, for the Hebrew verb tense is one that does not exist in English and corresponds to all time – past, present and future.
November 10, 2015 at 6:30 pm
Hi, Phillip Helbig.
The known laws of physics provide the mechanism for the universe’s collapse. As required by the Standard Model of particle physics, the net baryon number was created in the early universe by baryogenesis via electroweak quantum tunneling. This necessarily forces the Higgs field to be in a vacuum state that is not its absolute vacuum, which is the cause of the positive cosmological constant. But by sapient life annihilating the baryons in the universe via the inverse of baryogenesis, again via electroweak quantum tunneling (which is allowed in the Standard Model, as baryon number minus lepton number, B – L, is conserved), this will force the Higgs field toward its absolute vacuum, cancelling the positive cosmological constant and thereby forcing the universe to collapse. Moreover, this process will provide the ideal form of energy resource and rocket propulsion during the colonization phase of the universe.
Regarding how the known laws of physics (viz., the Second Law of Thermodynamics, General Relativity, and Quantum Mechanics) in the form of Prof. Frank J. Tipler’s Omega Point cosmology uniquely conform to, and precisely match, Christian theology:
The Omega Point is omniscient, having an infinite amount of information and knowing all that is logically possible to be known; it is omnipotent, having an infinite amount of energy and power; and it is omnipresent, consisting of all that exists. These three properties are the traditional quidditative definitions (i.e., haecceities) of God held by almost all of the world’s leading religions. Hence, by definition, the Omega Point is God.
The Omega Point final singularity is a different aspect of the Big Bang initial singularity, i.e., the first cause, a definition of God held by all the Abrahamic religions.
As well, as Stephen Hawking proved, the singularity is not in spacetime, but rather is the boundary of space and time (see S. W. Hawking and G. F. R. Ellis, The Large Scale Structure of Space-Time [Cambridge: Cambridge University Press, 1973], pp. 217-221).
The Schmidt b-boundary has been shown to yield a topology in which the cosmological singularity is not Hausdorff separated from the points in spacetime, meaning that it is not possible to put an open set of points between the cosmological singularity and *any* point in spacetime proper. That is, the cosmological singularity has infinite nearness to every point in spacetime.
So the Omega Point is transcendent to, yet immanent in, space and time. Because the cosmological singularity exists outside of space and time, it is eternal, as time has no application to it.
Quite literally, the cosmological singularity is supernatural, in the sense that no form of physics can apply to it, since physical values are at infinity at the singularity, and so it is not possible to perform arithmetical operations on them; and in the sense that the singularity is beyond creation, as it is not a part of spacetime, but rather is the boundary of space and time.
And given an infinite amount of computational resources, per the Bekenstein Bound, recreating the exact quantum state of our present universe is trivial, requiring at most a mere 10^123 bits (the number which Roger Penrose calculated), or at most a mere 2^10^123 bits for every different quantum configuration of the universe logically possible (i.e., the powerset, of which the multiverse in its entirety at this point in universal history is a subset of this powerset). So the Omega Point will be able to resurrect us using merely an infinitesimally small amount of total computational resources: indeed, the multiversal resurrection will occur between 10^-10^10 and 10^-10^123 seconds before the Omega Point is reached, as the computational capacity of the universe at that stage will be great enough that doing so will require only a trivial amount of total computational resources.
Miracles are allowed by the known laws of physics using baryon annihilation, and its inverse, by way of electroweak quantum tunneling (which, as said, is allowed in the Standard Model of particle physics, as baryon number minus lepton number, B – L, is conserved) caused via the Principle of Least Action by the physical requirement that the Omega Point final cosmological singularity exists. If the miracles of Jesus Christ were necessary in order for the universe to evolve into the Omega Point, and if the known laws of physics are correct, then the probability of those miracles occurring is certain.
Additionally, the cosmological singularity consists of a three-aspect structure: the final singularity (i.e., the Omega Point), the all-presents singularity (which exists at the boundary of the multiverse), and the initial singularity (i.e., the beginning of the Big Bang). These three distinct aspects which perform different physical functions in bringing about and sustaining existence are actually one singularity which connects the entirety of the multiverse.
Christian theology is therefore preferentially selected by the known laws of physics due to the fundamentally triune structure of the cosmological singularity (which, again, has all the haecceities claimed for God in the major religions), which is deselective of all other major religions.
For much more on the above, and for many more details on how the Omega Point cosmology uniquely and precisely matches the cosmology described in the New Testament, see my following two articles (links to which are provided in my original post in this thread):
* James Redford, “The Physics of God and the Quantum Gravity Theory of Everything”, Social Science Research Network (SSRN), Sept. 10, 2012 (orig. pub. Dec. 19, 2011), 186 pp., doi:10.2139/ssrn.1974708.
* James Redford, “Video of Profs. Frank Tipler and Lawrence Krauss’s Debate at Caltech: Can Physics Prove God and Christianity?”, alt.sci.astro, Message-ID: jghev8tcbv02b6vn3uiq8jmelp7jijluqk[at sign]4ax[period]com , July 30, 2013.
November 10, 2015 at 6:37 pm
Hi, Anton Garrett. The following provides a link to the paper under discussion:
* Frank J. Tipler, “Quantum nonlocality does not exist”, Proceedings of the National Academy of Sciences of the United States of America, Vol. 111, No. 31 (Aug. 5, 2014), pp. 11281-11286, doi:10.1073/pnas.1324238111, http://pnas.org/content/111/31/11281.full.pdf .
What physicist and mathematician Prof. Frank J. Tipler’s foregoing paper demonstrates is that a large portion of the physics community has falsely and unthinkingly assumed that experimental confirmations of quantum entanglement meant that nonlocality is real. Tipler’s said paper shows that that assumption doesn’t follow, and it is invaluable in clearing away the miasma of befuddled thinking that has long lain over the physics community regarding this subject.
Moreover, if one accepts the validity of General Relativity (which has been confirmed by every experiment to date), then nonlocality does not exist, since the speed of light is the fastest anything can travel, and therefore the multiverse of the Many-Worlds Interpretation logically must exist (i.e., due to the reason given in Prof. Tipler’s above paper: that experiments of quantum entanglement actually involve three measurements within the multiverse rather than two measurements within a single universe).
The assumption that General Relativity does not apply to quantum entanglement is an invalid presupposition which came from assuming that quantum entanglement necessarily had to have a nonlocal explanation, and hence experiments confirming quantum entanglement were erroneously taken to confirm that General Relativity is not valid when applied to such quantum mechanical phenomena. Since this assumption of nonlocality is a non sequitur, this means that there has never been any experimental evidence that anything travels faster than the speed of light.
Given that there has never been any empirical evidence for superluminal-speed phenomena, unless and until such time as said experimental evidence should be forthcoming, then there exists no rational reason to believe that the speed-restriction imposed by General Relativity can be violated (not counting the always-known mathematical exception of when energies become infinite).
Therefore, when the speed-restriction required by General Relativity is taken into account, what this further means is that the multiverse of the Many-Worlds Interpretation is experimentally confirmed to exist in doing quantum entanglement experiments.
And the existence of the multiverse can be experimentally confirmed in other ways: see Frank J. Tipler, “Testing Many-Worlds Quantum Theory By Measuring Pattern Convergence Rates”, arXiv:0809.4422, Sept. 25, 2008; and Frank Tipler, “Experimentally Testing the Mulitverse/Many-Worlds Theory”, American Astronomical Society 224th Meeting, June 1-5, 2014, #304.01 (June 4), bibcode: 2014AAS…22430401T.
Further, if Quantum Mechanics is true, then the multiverse’s existence follows as a mathematically-unavoidable consequence. For the details, see Frank J. Tipler, The Physics of Immortality: Modern Cosmology, God and the Resurrection of the Dead (New York, NY: Doubleday, 1994), pp. 483-488.
Regarding the theology of the Omega Point cosmology, see my two cited articles in my first post in this thread.
Concerning the matter you raised regarding miracles violating physical law, traditional Christian theology has maintained that God never violates natural law, as God, in His omniscience, knew in the beginning all that He wanted to achieve and so, in His omnipotence, He formed the laws of physics in order to achieve His goal. The idea that God would violate His own laws would mean that God is not omniscient. In traditional Christian theology, miracles do not violate natural law–rather, they are events which are so improbable that they can only be explained by the existence of God and His acting in the world. As Augustine of Hippo wrote concerning miracles [The City of God, Book 21, Ch. 8],
“”
For we say that all portents are contrary to nature; but they are not so. For how is that contrary to nature which happens by the will of God, since the will of so mighty a Creator is certainly the nature of each created thing? A portent, therefore, happens not contrary to nature, but contrary to what we know as nature.
“”
That is, traditional Christian theology has maintained that if we had the ultimate physical law, then we would be able to explain how God’s existence and His miracles are possible (cf. Romans 1:19,20; Thomas Aquinas, The Summa Theologica, 1st Part, Question 2, Arts. 2-3).
November 10, 2015 at 7:49 pm
@James Redford
Non-locality is an artifact of psi-ontology not, as Tipler claims, of the (psi-epistemic) Copenhagen interpretation: http://www.mth.kcl.ac.uk/~streater/EPR.html and MWI is not confirmed (relative to CI or other psi-epistemic interpretations) by experiment. MWI proponents keep making false claims of this sort – they seem to be incapable of not thinking psi-ontically – and it’s infuriating.
November 10, 2015 at 7:59 pm
James,
Above, I gave specific reasons why Tipler was wrong about nonlocality, having read online the Abstracts of two of his papers about it; those Abstracts were quite clear enough for me to understand what his claims are. Please engage with what I already wrote on this thread about Tipler’s arguments. I’ll add that Bell’s analysis can equally well be used to determine whether two people being interrogated in different rooms are in clandestine contact in coordinating their replies, beyond having merely pre-agreed their answers to a set of questions which they might be asked. So it is not about quantum mechanics at all. For more detail of my explanation of nonlocality, see my discussion on this very blog:
https://telescoper.wordpress.com/2015/08/03/guest-post-hidden-variables-just-a-little-shy/
Incidentally (and as detailed at that link) I agree with you that superluminality is unphysical. However, the fact that in Bell-type experiments the order of the measurements on the two particles is not Lorentz-invariant suggests that something very weird is going on. I take that something to be acausality, because acausality is forced already in Wheeler delayed-choice experiments that test quantum mechanics. See again the link for details. See it also for an expansion of my comments against the many-worlds interpretation. Many-worlds is not the same as the multiverse, of course.
Some theological questions:
Is the Omega Point a volitional being?
Did the Omega Point create the universe and everything that is not itself?
How can you use Omega Point theory/theology to single out Christianity from Islam or some other religion? I find the analogy between the Holy Trinity of Father, Son and Holy Spirit, and the initial singularity, the final singularity and the singularity at the boundary of the multiverse, to be a little strained.
How can you relate Omega Point theology to the question of sin and salvation?
Is it not absurd to suggest that St Peter violated no laws of physics given that he walked on water yet began to sink as his faith wavered? (Matthew 14:25-31)
November 11, 2015 at 11:40 am
Let’s not forget Newton’s greatest accomplishment: Dying a virgin!
November 11, 2015 at 12:55 pm
AFAIK, it’s hearsay that he claimed his greatest accomplishment in life was maintaining his virginity, but that’s just too juicy a target to ignore. 😉
November 9, 2015 at 5:18 pm
Regarding: “The crucial point about this methodology is that it is inherently inductive: all the reasoning is carried out in “hypothesis space” rather than “observation space”. The primary form of logic involved is not deduction but induction.”
However, remember that Bayes’ theorem is simply a theorem. You don’t magically get out of it something that goes beyond the assumptions (‘premises’) you initially put into it. So, while it can be used for inductive reasoning, it is not inductive itself- it is deductive. The reason it can be used as a framework for inductive reasoning is that the values one plugs into Bayes already incorporate certain inductive assumptions (e.g., when we assign a uniform prior).
For further discussion of this point, see Colin Howson’s book: Hume’s Problem.
November 10, 2015 at 9:13 am
David Hume argued that you cannot infer anything about the unseen from the related seen, because it is unseen. The consequence is that if you are told that a sack contains 100 apples and the first 70 (say) that you pull out are all rotten, you cannot say anything at all in advance about the state of the next one you pull out. Or that the fact the sun has been observed by humans to rise every day for thousands of years is no ground for supposing it will do so again 24 hours from now.
Philosophers rather confusingly call Hume’s scepticism of inductive logic his “inductive scepticism”. Hume has made no technical error, but he is restricted. IF you suppose that you can generalise deductive Boolean logic such that one proposition implies or disproves another – not with certainty but to a certain extent – then you can explore the resulting generalised logic. And what you find is something that becomes recognisable as the way humans reason every day in the absence of certainty. We live our lives as if we are very confident that the sun will rise tomorrow, for instance.
RT Cox (mentioned above in this thread) showed that what you get is the laws of probability, as applied in probabilistic inference. They had, obviously, been known before Cox, but he established a new basis for them that gave us a deeper understanding of them.
I’m familiar with Howson’s name although I’ve not read that particular book. Therefore I’ve nothing to say about it, but I will add that philosophers are in a state of deep confusion about the relation between probability and inductive logic. Popper, for instance, accepted the former while rejecting the latter. He seemed, like too many people, unaware of Cox’s work.
November 10, 2015 at 8:54 am
You say: “The question is whether they would make ALL life impossible”. That’s a very interesting question, but it is not quite the question that the anthropic principle deals with, which is: what does OUR presence tell us about the physical universe? To begin answering that question you have to decide which features of human life are relevant – intelligence, bipedalism, etc. And at this point we are into evolutionary biology.
I wold not be surprised if the universe is teeming with bugs but multicellular life is so rare as to be unique. Some very well argued conjectures about how unicellular life evolved into multicellular are contained in a remarkable book by Nick Lane called The Vital Question, published earlier this year. If Lane is right, it took a very special environment indeed.
November 10, 2015 at 9:29 am
Well, if some things, e.g. the fine structure constant, were slightly different there wouldn’t even be atoms…
November 10, 2015 at 9:39 am
Monty Python on the anthropic principle:
November 10, 2015 at 9:52 am
I need mine.
November 16, 2015 at 6:29 pm
“[…] but the probability of a model given the data is generally not the same as the probability of the data given the model. I’m amazed how many practising scientists make this error on a regular basis.”
Somewhere I don’t remember I read a nice example of that difference: the probability of having a son or daughter (data) conditioned on being a woman (hypothesis) is certainly not the same as the probability of the opposing conditioning.
November 17, 2015 at 9:25 pm
The version I am familiar with is that the probability of a person being pregnant conditioned on being a woman is different from the probability of a person being a woman conditioned on the person being pregnant.
November 17, 2015 at 9:29 pm
Certainly! I should have written “given birth”.
November 25, 2015 at 11:58 pm
“Since life is observed in our Universe the model-parameters which make life more probable must be preferred to those that make it less so.”
To me that sounds like saying that if a die is cast once and lands with 6 on top then we should prefer those theories of casting a die which predict a 6 with high probability!
I am sorry, but the observation of life on a single planet in the observable universe says NOTHING about the probability of occurrence of life in the universe.
November 26, 2015 at 9:51 am
The observation of life tells you at least that the probability of life is not zero…
It’s quite easy to use Bayes’ theorem to work out the relative probabilities in dice games.
Suppose you have two dice, one (A) normal and another (B) with a six on all six faces. The probability of throwing a six given A is 1/6. The probability of throwing a six given B is 1. If you have no other information to distinguish between the two you can assign a prior probability of 1/2 to each case.
Now use Bayes’ theorem to work out the probability of the die being B when you find that you have thrown a six…
November 26, 2015 at 12:05 pm
Excellent, Telescoper!
To Arko, I would also like to point out how “favorable” our universe is to biological life.
Life as we know it is, in fact, so rare that some of the largest projects in history over centuries of looking have failed to find anything anywhere but the surface of Earth, and tenuous indications of microbes once existing on ancient Mars.
As a percent of life per volume, the universe appears more than equal to industrial-strength, disinfection and sterilization techniques of any hospital in the world.
“Favorable” hardly seems appropriate – and IMHO: we are very lucky to be able to even debate the point 🙂
November 26, 2015 at 1:59 pm
It appears to me that (correct me if I am wrong) you are saying that our universe has a very low probability for the appearance of life.
If that’s the case, we should prefer theories that do not predict a high probability for the appearance of life in the universe.
November 26, 2015 at 1:54 pm
A universe with low probability for life may also have life, but its model will be different from another that predicts a high probability for life in a universe.
Thus, just the presence of life on one planet is inadequate data to say anything about the probability – as against the mere possibility – of life in the universe.
November 26, 2015 at 9:46 pm
While I’m not saying that, your inference that I would generally agree with “a very low probability for the appearance of life” is probably accurate, given lots of caveats.
“Appearance of life” can be tricky, I think.
We might think bio-genesis, detection/observation, or detection of bio-genesis process.
As for normative “shoulds”, absent any other information than lots of evidence that life appears extraordinarily rare, I think it comes down to tweaking Bayesian models that and what we mean by “high” probability.
If we’re running a bajillion-to-one numbers lottery, a winning ticket even existing might seems very low, whereas if we run the lottery a mega-bajillion-bajillion times, we could say a very low probability outcome is absolutely assured.
Is that a high probability? I’d say it depends on what we mean.
December 28, 2022 at 9:08 am
Life schedule leave
Life as a Condition of Cosmology | In the Dark